Visualizzazione post con etichetta research. Mostra tutti i post
Visualizzazione post con etichetta research. Mostra tutti i post
venerdì 16 novembre 2012
Some work on Aglets after all!
I don't remember the last time I did some work on the Aglets platform, but in the last days something have moved. Thanks to the great work by Thomas, the platform is moving to a much more easy deployment. I took the chance to do a code clean up and to fix some annoying problems with the terrible AGLETS_HOME variable and file paths that were referring to it.
venerdì 29 giugno 2012
Autonomous Role Discovery for Collaborating Agents

I'm proud to announce that a paper I wrote with my colleague and friend prof. Haibin Zhu has been published on-line on Software Practice and Experience (SPE). The paper, titled, Autonomous Role Discovery for Collaborating Agents , can be found here.
This is the result of the last year efforts on the WhiteCat framework.
JFK and Roles....
With the help of a friend of mine a work on roles applied to the JFK framework is ongoing. It is still early to present some results, and it is quite difficult to even imagine the final result, that came into my mind from Object Teams. We'll see!
mercoledì 10 agosto 2011
FLAP is now available as Open Source

A few days ago I created a repository on GitHub to host a few bits of source code: Ferrari Luca's Agent Platform (FLAP). This tiny project is a Java agent platform inspired by Aglets that I used during a course I did at the University of Modena and Reggio Emilia in late 2006. My idea was to present students with a simple agent platform, easy to understand and to debug, in order to make they understand the main concept behind concurrency, thread management and agent messaging a platform must accomplish. The platform represents also a good starting point to do experiments against agent algorithms and theories, and it is for this reason I'm releasing this as Open Source. You are free to experiment and improve the platform as much as you want, but please take into account that the platform is intended to be a didactic workbench, not a professional or complex product. The code compiles with Apache Maven, and if you run test you will actually prompted with a micro interactive shell.
The code is released under the BSD license, so you are really free to do whatever you want with it. But if you find it useful in your courses, studies, free time, please let me know.
{kind=link}
domenica 10 aprile 2011
WhiteCat @ CTS 2011
I'm proud to announce that WhiteCat has been accepted as regular paper work at CTS 2011. The paper that will be presented at the conference shows improvements since the past versions of the framework. Moreover the paper presents a bird's eye view of the framework itself demonstrating its integrability with other role and agent systems.
venerdì 1 aprile 2011
Joining the IJATS ERB
I'm proud to announce that the Editor in Chief has officially asked me to become a member of the Editorial Review Board of the International Journal of Agent Technologies and Systems. And I'm happy to say I accepted this opportunity, so now I'm officially on the Editorial Review Board of IJAS.
This means that I will be selected to do paper reviews and to evaluated scientific works submitted to this journal. I see this as an opportunity to improve my scientific skills and I'll do my best to peer review every work I will be ask to review.
This means that I will be selected to do paper reviews and to evaluated scientific works submitted to this journal. I see this as an opportunity to improve my scientific skills and I'll do my best to peer review every work I will be ask to review.
mercoledì 29 settembre 2010
WhiteCat: scheduling tasks depending on role events
I spent a few hours making what seemed a little change to the WhiteCat code, but that soon resulted in a very complex and refactoring-based change: implementing a task scheduler driven by role events.
WhiteCat already publishes role events when a role is assumed or released, based on that and on the last change on role tasks, the idea is to allow an agent to schedule the execution of a role task as soon as the role is assumed by another agent or before the role is released by an agent. The scenario this change covers is that of asynchronous inter-agent collaboration: an agent can ask another agent to do something once it is ready to do it. To get it simple, consider a scenario where a person goes to work, and assume an employee role; thanks to the scheduling another agent is able to "ask" the former to perform a phone call as soon as it is at the office (i.e., as soon as it assumes the employee role). It is like when you say "call me when you are in office" to a friend of yours, or at the opposite "call me before you get home".
Now to get into details, the scheduler is fully configured thru Spring and an agent can specify to the scheduler to perform a task specific to a role by a specific agent or by the first agent that is going to assume/release such role. Of course, the event the task must be performed will be specified at the time of the scheduling, so an agent has the following choice for scheduling a task:
- the task to schedule (of course)
- an agent that must perform the task or any agent that is able to do the task (i.e., any agent that is going to assume/release the role the task belongs to)
- when the task must be executed (after the role assumption or before the role release)
This allows for new dynamic and collaborative solutions in the agent/role modelling! The current implementation exploits AOP to deal with the event dispatching and the task schedulation. Several changes have been done to all the system, starting from the task execution, that now has a task return type that wraps the result of the execution and implements a simple "future reply" pattern, the event dispatching, that now allows for notification of all events no matter of which agent id they are related to, role descriptors and repository, that now are more powerful for inverse role lookup and so on. During the coding several problems have been fixed, and new tests have been added to the code base.
Of course, all the code is available thru the git repository.
Drawbacks of this implementation are present, of course: the scheduling is related to a single role instance, and this could be fixed in future releases since it is based on the role repository. Moreover, it could be interesting to implement a real "do it for me" mechanism, where the execution of the task is totally in charge of the agent running the role (i.e., a pure message based system).
sabato 14 agosto 2010
JFK: implementing a raw yield return
A new feature has been added to JFK: a raw support for the yield return.
Before explaining it, please consider the cases when a yield return is useful: you are iterating over an iterator and want to return, one at a time, the next value extracted from the iterator.
Consider the following method:
public int cycle(){
for( int i : this.myIterable )
return (i*i);
return 0;
for( int i : this.myIterable )
return (i*i);
return 0;
}
Now, supposing myIterable is an integer iterable that returns numbers from 0 to 1000, the above method does not cycle on all the values, but returns always the first element in the iterator (so it is 0). The adoption of yield return allows the iterator to return the next value each time the method is called.
At the time of writing, JFK supports yield return when using iterators, and to get this support developers have to:
- use a class-level iterator (i.e., not in a local method scope);
- annotate the iterator with the @Yield annotation to inform JFK that the adoption of such iterator can be yielded. Since JFK must have access to the iterator, in the case the latter is private, developers can indicate in the annotation a get method for the iterator itself.
- ask JFK to build an instance that exploits the yield return.
The important thing to note in the above duties is that no special bareword or special objects must be used by developers: the methods are written as in normal Java.
So, taking back the above cycle method example, supposing the myIterable object has been annotatoted with the @Yield annotation, the following code will produce a progressive output:
IYieldBuilder yBuilder = JFK.getYieldBuilder();
// GoodYielder is an objet with the cycle method
GoodYielder gy = (GoodYielder) yBuilder.buildYielder( GoodYielder.class );
for( int i = 0; i < 10; i++ )
System.out.println("Cycling with yield: " + gy.cycle() );
GoodYielder gy = (GoodYielder) yBuilder.buildYielder( GoodYielder.class );
for( int i = 0; i < 10; i++ )
System.out.println("Cycling with yield: " + gy.cycle() );
will produce
Cycling with yield: 1
Cycling with yield: 4
Cycling with yield: 9
Cycling with yield: 16
Cycling with yield: 25
Cycling with yield: 36
Cycling with yield: 49
Cycling with yield: 64
Cycling with yield: 81
Cycling with yield: 100
The current support to yield return is really minimal and useful for a limited set of use cases. I'm currently investigating a more complete and general approach, keeping into account that no syntactic or semantic overhead will be introduced: the yielding must be declarative!
In the meantime, if you need a more complete yielding mechanism (which is very different in syntax and semantic to JFK aim) have a look at Java Yielder here.
martedì 3 agosto 2010
JFK: Java Methods on Steroids
Warning: if you got here searching for some information about the 35th president of the United States of America, you are in the wrong place! This post (and related ones) have nothing to do with politics or the above president, this is only Java!
Another warning: I have some strong opinions. You can disagree with me
as much as you want, but please keep in mind I'm open only
to constructive discussions.
JFK stands for Java Functional Kernel, and it is a framework that brings function power to the Java World. Java does not use the term "function", preferring the term "method", but the two are, at least for what concerns JFK, the same. A function/method is a code block that you can call passing arguments on the stack and getting back a result.
But while in Java first-class elements are classes, and therefore you cannot abstract a method outside a class, JFK brings the power of function pointers to Java, allowing you to use functions (or methods, if you prefer such term) as first-class entities too.
"Wait a minute, Java does not allow function pointers!"
That is true, standard Java does not allow them, but JFK does.
"I don't need function pointers in Java, Java is a modern OOP language where function pointers are not useful and, besides, I think they are evil!"
If this is what you are thinking, well, I will not call you idiot because I'm polite, but you probably should not read this; you should go back to your seat and continue typing on your keyboard some standard Java program.
"An OOP language cannot admit function pointers!"
Ok, now I'm really thinking you are an idiot, so please move away. Being OOP does not mean that function pointers are not allowed, but rather that they must be objects too.
Now if you think this can bring a new way of developing Java applications and can increase your expressiveness, keep reading.So what do you get with JFK?
JFK enables you to exploit three main features:
- function pointers
- closures
- delegates (in a way similar to C#)
Please take into account that JFK is not reflection! Java already has something similar to a function pointer, that is the Method object of the reflection package, but JFK does not use it. In JFK everything is done directly, without reflection in order to speed up execution.
Function pointers
The first question is: why do I need function pointers? Do I really need an abstraction over methods/functions? Well, I think YES!
As well as OSGi provides a mechanism to exports only some packages at run-time, function pointers provide the ability to export functions without having to export objects. To better understand, imagine the following situation: you've got an object (Service Object) that has two service methods, called M1 and M2. Now you've got two processes (whatever a process means to you) that must use only one of the methods, so imagine that the first process must use M1 and the second one M2. Being M1 and M2 defined in the same class, the only solution is to share the service object among the two processes, as shown in the following picture.

This solution is no modular at all, since both processes must keep a reference to a shared object. A better solution, without having to write a wrapper object for every method, is to create a set of interfaces, each one tied to a method. In this way the service object can implement every interface it must expose, and the processes can hold a reference to the interface (and therefore to the service object). The situation is shown in the following figure.

This approach has several drawbacks:
- a new interface is needed to modularize every exposed method;
- it is still possible to inspect, thru reflection, the reference and understand which object it is "hiding".
The (1) requires developers to write a lot of code, and this is what happens with normal event handlers, such as ActionListener: you have to declare a single-method interface for every method you want to expose. The (2) is a security hole: with reflection the reference holder can inspect the object and understand it has the method M2 and even call it.
So, while very OOP, this approach has limitations that can be overtaken with the adoption of function pointers.
With function pointers it is possible to expose only pointers to a method M1 or to M2 without having to expose the object (or its interfaces) to the consumer processes, as shown in the following picture.

This is a very modular way of doing things: you don't have to worry about the service object, introspection against it, or even where the object is stored/held: you are passing away only the pointer to one of the functions and the receiver process will be able to exploit only the method/function behind such pointer.
"Ok, I can get this for free with java.lang.reflect.Method objects"
Again, this is not reflection! Reflection is slow. Reflection is limited. This is a direct method call thru a pointer object! And no, this is not a fancy use of proxies/interceptors! Note that with reflection you are able to invoke only local methods, while with JFK you are free to call even remote functions without having to deal with RMI objects and stubs. At the moment this feature is not implemented yet, but it is possible. Please keep into account that, at the time of writing, JFK is still a proof of concept, so not all possible features have been implemented!
Keeping an eye on security, JFK does not allow a program to get a function pointer to any method available in a class/object, a method must be explicitly exported, that is when you define a class and its methods, you have to explicitly mark the methods you want to be able to be pointed. This allows you to define with a fine grain what services (as functions) each calss must export. Exporting a method is really simple, you have to mark it with the @Function annotation indicating the method name, that is an identifier that is used to refer to that specific method (it can be the same as the method name or something with a different meaning, like 'Service1'). Let's see an example:
public class DummyClass {
public final String resultString = "Hello JFK!";
public String aMethodThatReturnsAString(){
return resultString;
}
@Function( name = "double" )
public Double doubleValue( Double value ){
return new Double( value.doubleValue() * 2 );
}
@Function( name = "string" )
public String composeString( Integer value ){
return resultString + value.intValue();
}
@Function( name = "string2" )
public String composeStringInteger(String s, Integer value ){
return s + value.toString();
}
}
public final String resultString = "Hello JFK!";
public String aMethodThatReturnsAString(){
return resultString;
}
@Function( name = "double" )
public Double doubleValue( Double value ){
return new Double( value.doubleValue() * 2 );
}
@Function( name = "string" )
public String composeString( Integer value ){
return resultString + value.intValue();
}
@Function( name = "string2" )
public String composeStringInteger(String s, Integer value ){
return s + value.toString();
}
}
The above class exports three instance methods, with different identifiers. For instance the method composeStringInteger is exposed with the identifier of 'string2'. This can be used from a program in the following way:
// get a pointer to another function
// the "double" function returns a computation of a double
// passed on the stack (dummy is a DummyClass instance)// the "double" function returns a computation of a double
IFunction function = builder.bindFunction(dummy, "double" );
dummy = null; // note that the dummy object is no more used!!!
Double d1 = new Double(10.5);
Double d2 = (Double) function.executeCall( new Object[]{ d1 } );
System.out.println("Computation of the double function returned " + d2);
// it prints
// Computation of the double function returned 21.0
As you can see, you can obtain a function pointer to an object method that is marked as 'double', and then executes the function with the IFunction.executeCall(..). That's so easy!
So to recap, you can get an IFunction object bound to a method identified by an exposing name, and you can execute the executeCall method on such IFunction in order to execute the function pointed. I stress it again: this is not reflection! Moreover, IFunction is an interface without an implementation, that means there is nothing static here, all the code is dynamically generated at run-time.
Being dynamic does not mean that there are not checks and constraints: before invoking the function, the system checks the arguments number, the argument type and so on and throws appropriate exceptions (e.g., BadArityException).
Now, inspecting the stack trace of the IFunction.executeCall(..) you will never see a Method.invoke(..) or stuff like that (do you remember that this is not reflection?).
Performances are really boosted with JFK when compared to reflection. For instance, the method call of the 'double' function requires around 12850 nanoseconds with JFK, while it requires 324133 nanoseconds using reflection (in particular 292914 ns to find the method and 31219 ns to invoke it). So a simple method execution goes 25 times faster, and even more: since IFunction objects are cached, once they are bound to a function, the execution of the pointer is almost immediate!
Closures
Closures are pieces of anonymous code that can be executed as first-class entities. To say in simple words, closures are like Java methods that can be defined on the fly and that are not belonging to any special class.
Java does not support closures, but something similar can be obtained with inner anonymous classes. Having function pointers, closures come almost for free, so that in you code you can do something like the following:
IClosureBuilder closureBuilder = JFK.getClosureBuilder();
IFunction closure = closureBuilder.buildClosure("public String
IFunction closure = closureBuilder.buildClosure("public String
concat(String s, Integer i){ return s + i.intValue(); }");
// now use the closure, please note that there
// now use the closure, please note that there
// is no object/class created here!
String closureResult = (String) closure.executeCall( new Object[]{
String closureResult = (String) closure.executeCall( new Object[]{
"Hello JFK!", new Integer(1234) } );
System.out.println("Closure result: " + closureResult);
// it prints
// Closure result: Hello JFK!1234
System.out.println("Closure result: " + closureResult);
// it prints
// Closure result: Hello JFK!1234
Closures are defined as IClosure objects, that are a special case of IFunction objects. While IFunction objects point to an exisisting method, IClosure objects point to a method that is still not existing and that is not exposed thru any class/object. Again, there is no reflection here, and there is no static implementation of IClosure available. Execution times are on the same order of IFunction ones, but closures are not cached in any way, since they are thought to be one-shot execution unit. I haven't inspected if my approach is the same as of Groovy closures, I suspect there is something similar here.
Delegates
Delegates are something introduced by C# to allow an easy way to simulate function pointers for event handling. JFK provides a declaritive way of defining delegates and their association that is somewhat similar to the signal-slot mechanism of Qt. First of all a little of terminology:
- a delegate is the implementation of a behaviour (this is similar to a slot in the Qt terminology)
- a delegatable is an object and/or a method that can be bound to a delegate, so to a concret implementation (this is similar to a signal in the Qt terminology)
The idea that leads JFK delegates has been the following:
- delegatable methods could be abstract (the implementation does not matter when the delegate is declared)
- adding and removing a delegate instance should be dynamic and should not burden the delegatable instance
Let's see each point with an event based example; consider the following event generator class:
public abstract class EventGenerator implements IDelegatable{
public void doEvent(){
for( int i = 0; i < 10; i++ )
this.notifyEvent( "Event " + i );
}
@Delegate( name="event", allowMultiple = true )
public abstract void notifyEvent(String event);
}
The above EventGenerator class is a skeleton for an event provider, such as a button, a text field, or something else. The idea is when the doEvent() method is executed an event is dispatched thru the notifyEvent(..) method. As you can see the (1) states that the notifyEvent(..) method can be abstract, as it is in this example. The idea is that, since the notifyEvent(..) should have the implementation done by someone else (the event consumer), its implementation does not matter here. Letting the delegatable method abstract means that you cannot instantiate the object EventGenerator without having bound it to a method implementation. If you need to be able to instantiate it, you can provide a body method (even empty) keeping in mind that it will be replaced by a connection with the delegate that must execute the method. The delegatable method must be annotated with the @Delegate annotation, where you can specify a name (that is similar in aim to the function name) and a flag that states if the delegatable can be connected to multiple delegates. And here comes the (2): note how the delegatable method is called once. Even when multiple delegates are connected to the delegatable the JFK kernel takes care of the execution of all the delegates. In standard Java you have to write:
public void doEvent(){
for( int i = 0; i < 10; i++ )
for( int i = 0; i < 10; i++ )
for( MyEventListener l : this.listeners )
l.notifyEvent( "Event " + i );
}
l.notifyEvent( "Event " + i );
}
having listeners and MyEventListener respectively a list of listeners and the interface associated to the listener. Can you see the extra loop to notify all the listeners? It means that the producer has to keep track of all the consumer, and this is wrong! It strictly couples the consumer to all the producers, and this is an awkward implementation. In fact, I think that the event mechanism as implemented by standard Java is not an uncoupling mechanism, and this is why I tend to prefer AspectJ/AOP event notifications (as implemented in WhiteCat). Again, there is no reflection here, and the kernel is not keeping track of all the consumers, rather it manages a set of function pointers to consumers. It's that easy!
Now let's see how you can use the delegates; first you have to implement a behaviour for the delegate, assume we have the following two:
public class EventConsumer implements IDelegate{
@Connect( name="event" )
public void consumeEvent(String event){
System.out.println("\n\t********** Cosuming event "
@Connect( name="event" )
public void consumeEvent(String event){
System.out.println("\n\t********** Cosuming event "
+ event + "\n\n\n");
}
}
}
}
public class EventConsumer2 implements IDelegate {
@Connect( name="event" )
public void consumeEvent2( String e ){
System.out.println("\n\t**********>>>>>>>
@Connect( name="event" )
public void consumeEvent2( String e ){
System.out.println("\n\t**********>>>>>>>
Cosuming event " + e + "\n\n\n");
}
}
}
}
Both the event consumer have a method with the same signature of the delegatable one; the JFK kernel checks before binding methods that the signature are compatible. Both methods are annotated with the @Connect annotation that specifies the same name of the delegatable to which connect to. Now you can write a program that does the following:
IDelegateManager manager = JFK.getDelegateManager();
IDelegatable consumer = (IDelegatable) manager.createAndBind(
IDelegatable consumer = (IDelegatable) manager.createAndBind(
EventGenerator.class, new EventConsumer() );
// now the delegate will invoke the abstract method,
// now the delegate will invoke the abstract method,
// that has been defined at run-time to match the
// consumer method in the EventConsumer object
((EventGenerator) consumer).doEvent();
// it prints
// ********** Cosuming event Event 0
// ....
// ********** Cosuming event Event 9
// now it is possible to add another consumer to the event generator,
// consumer method in the EventConsumer object
((EventGenerator) consumer).doEvent();
// it prints
// ********** Cosuming event Event 0
// ....
// ********** Cosuming event Event 9
// now it is possible to add another consumer to the event generator,
// since it allows a multiple
// connection. To do this, we can add another delegate to the instance
manager.addDelegate(consumer, new EventConsumer2() );
// now the delegate will invoke the abstract method,
// connection. To do this, we can add another delegate to the instance
manager.addDelegate(consumer, new EventConsumer2() );
// now the delegate will invoke the abstract method,
// that has been defined at run-time to match the
// consumer method in the EventConsumer object
((EventGenerator) consumer).doEvent();
// consumer method in the EventConsumer object
((EventGenerator) consumer).doEvent();
// it prints
// ********** Cosuming event Event 0 <- from EventConsumer// **********>>>>>>> Cosuming event Event 0 <- from EventConsumer2
// ....
// ********** Cosuming event Event 9 <- from EventConsumer
// **********>>>>>>> Cosuming event Event 9 <- from EventConsumer2
First of all you need a delegate manager to which you ask to instantiate an EventGenerator object (you cannot instantiate it directly in this example because it has abstract methods) binding it to an EventConsumer instance. This produces a new instance of EventGenerator that will call and execute EventConsumer.consumeEvent(..) each time EventGenerator.notifyEvent(..) is called. In the following, you can dynamically add (and remove) other delegates to the running instance of EventGenerator so that all the associated delegates will be executed when the EventGenerator.notifyEvent(..) method is called. I stress it again: note that the event generator do not deal with all the possible event consumers, the JFK kernel does it! And again, there is no reflection involved here, everything happens as a direct method call!
The following picture illustrates how you can imagine the delegate works in JFK:

What else can I do with JFK?
Well, JFK is a functional kernel, so you can do whatever you do with functions. For instance you can pass a function pointer to another method/function, enabling functional programming!
The following picture illustrates how you can imagine the delegate works in JFK:

What else can I do with JFK?
Well, JFK is a functional kernel, so you can do whatever you do with functions. For instance you can pass a function pointer to another method/function, enabling functional programming!
A final note on reflection
In this article I wrote several times that JFK does not uses reflection. This is not true at all. As you probably noted the current implementation is based on annotations, and this means that in order to get annotations and their values, JFK needs reflection. The thing that must be clear is that method execution thru function pointers does not use reflection at all!
(Some) Implementation Details
I'm not going to show all the internals, for now it suffice to know that this project is developed in standard Java (J2SE6) and, strangely, it is still not an AspectJ project as I do for almost every project I run. All the configuration of the run-time system is done using Spring, and there is a suite test (Junit 4) that stress the system and its functionality.
Need more info?
Well, at the moment this is a private research project of mines, so I cannot show you all the details because they are still changing (but the API is stable). I've created a page on the Open Source University Meetup where discussions can happen, beside my blog. If you need more info, or want to collaborate at the project, feel free to contact me.
lunedì 2 agosto 2010
WiteCat now has a page on OSUM
I'm not sure it makes sense to have a page on OSUM, since the situation of what was Sun's is not clear to me, but I've created a page to make the WhiteCat project more visible. You can find the page here.
However, please take into account that the main information about the project will be available, of course, thru my blog.
I've used the same logo as it was adopted in the CTS 2010 poster.
lunedì 26 luglio 2010
Aglets 2.5
It took very much time to get to the new alpha release of the Aglets Mobile Agent Platform. The version is the 2.5, that creates an hole between the previous one, 2.0.2, but since there are so many improvements the I decided to make it clear that this is a version that has touched almost every part of the platform.
There are important changes, the much visible of which is the new GUI that is based on Swing and no more on AWT. The GUI has not been simply converted from AWT to Swing, but it has also been restructured in order to be simpler and more friendly to use, as well as of course include the new features.
Behind the hood, the platform now supports the sleeping of an agent in a manner similar to Thread.currentThread().sleep(), and a lot of classes have been adjusted to be type safe and better organized. This means that Aglets now requires a newer version of Java, in particular at least J2SE 6. The reason for that is the adoption of a fully integrated localization system that is based on J2SE 6 Resource Bundle, wrapped in an AgletTranslator object that allows the user, as well as agents, to get localized texts and icons.
Other improvements are related to the general management of the internal data structures, that has changed from slightly to deeply depending on the case.
You can download a zip archive containing the alpha release from here.
You can download a zip archive containing the alpha release from here.
I will thank everyone that assisted me in this long process, and I will apologize for this late releasing.
This release makes also the old web site to become unavailable, relying instead on the default Sourceforge web content (as shown below). The reason for this is that the old site was still linking the AgentGroup @ Unimore, that didn't help me within Aglets and, in fact, copied and paster part of my work within this project releasing it as their own! It is evident if you see the papers related to Aglets: the first in the list ((Leveraging strong agent mobility for Aglets with the Mobile JikesRVM framework. Scalable Computing: Practice and Experience) contains parts of the second article (Strong Agent Mobility for Aglets based on the IBM JikesRVM) that was written before with my contribution. So to get it short, I removed the web site with all references to Unimore. The following is how the site was appearing and how it appears now.


Here I post some screenshots from the new alpha release.
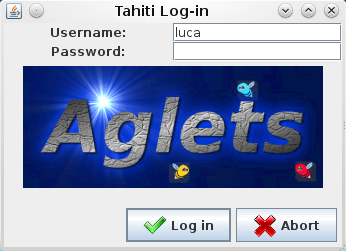






giovedì 22 luglio 2010
WhiteCat: role descriptors done right!
WhiteCat includes the concept of role descriptors it inherited from its precedessor, BlackCat.
A role descriptor is a layer of meta-information around a specific role implementation. The idea is that an agent can deal with a role descriptor in order to see what the role aims are, which operations the role provides and which events each operation will generated and/or receive. As readers can see, a role descriptor is not a single complex and big object, but a set of nested small objects each one tied to a specific piece of role information. This means that a role will have a RoleDescriptor as its top descriptive object, and the latter will contain one or more OperationDescriptor, that in turn can contain one or more EventDescriptor. This is the structure of role descriptors in BlackCat, that has been rewritten almost equally in WhiteCat.
In the last couple of commits I've changed this structure to a more flexible and powerful one. First of all, a role descriptor does not have anymore operation descriptors, but "task descriptors". A task descriptor describes a task (e.g., a method call). Most interesting is the Task itself, an interface to allow the composition of method calls and other tasks in order to obtain a very complex executional unit. Having the task abstraction, a role description now contains pure executable objects that will do a method call (or a method call chain) on a specific role. The task descriptor is useful to allow the agent to better understand the meaning of a task and to select it before it is executed. So the main difference between the BlackCat role descriptors and the WhiteCat ones is that in the new version the role descriptor contains also executable code as a task definition, as well as its description. The event descriptor has been kept unchanged, except that since the first version of WhiteCat it explicitly specifies if the event is incoming or outgoing.
A task can be executed or composed with another task, and this allows for a great reusability as well as modularity.
Another importan change is that now WhiteCat allows for annotation based descriptors: the role developer can annotate his role with special annotations in order to allow the system to infer the role descriptor automatically. The system now includes a interface, called IRoleDescriptorBuilder, that can analyze a role implementation (IRole) and create the descriptor depending on the annotation values.
This integration has several advantages, the most important of which is that the developer can write a single file (the role class implementation) letting the system to infer the role descriptor and the tasks. Of course, this can be overridden by a formal role descriptor expressed, for instance, as XML.
A role descriptor is a layer of meta-information around a specific role implementation. The idea is that an agent can deal with a role descriptor in order to see what the role aims are, which operations the role provides and which events each operation will generated and/or receive. As readers can see, a role descriptor is not a single complex and big object, but a set of nested small objects each one tied to a specific piece of role information. This means that a role will have a RoleDescriptor as its top descriptive object, and the latter will contain one or more OperationDescriptor, that in turn can contain one or more EventDescriptor. This is the structure of role descriptors in BlackCat, that has been rewritten almost equally in WhiteCat.
In the last couple of commits I've changed this structure to a more flexible and powerful one. First of all, a role descriptor does not have anymore operation descriptors, but "task descriptors". A task descriptor describes a task (e.g., a method call). Most interesting is the Task itself, an interface to allow the composition of method calls and other tasks in order to obtain a very complex executional unit. Having the task abstraction, a role description now contains pure executable objects that will do a method call (or a method call chain) on a specific role. The task descriptor is useful to allow the agent to better understand the meaning of a task and to select it before it is executed. So the main difference between the BlackCat role descriptors and the WhiteCat ones is that in the new version the role descriptor contains also executable code as a task definition, as well as its description. The event descriptor has been kept unchanged, except that since the first version of WhiteCat it explicitly specifies if the event is incoming or outgoing.
A task can be executed or composed with another task, and this allows for a great reusability as well as modularity.
Another importan change is that now WhiteCat allows for annotation based descriptors: the role developer can annotate his role with special annotations in order to allow the system to infer the role descriptor automatically. The system now includes a interface, called IRoleDescriptorBuilder, that can analyze a role implementation (IRole) and create the descriptor depending on the annotation values.
This integration has several advantages, the most important of which is that the developer can write a single file (the role class implementation) letting the system to infer the role descriptor and the tasks. Of course, this can be overridden by a formal role descriptor expressed, for instance, as XML.
WhiteCat: other branches merged!
I've merged other two branches within the WhiteCat project and published them on the public available SourceForge repository.
These changes involve the locking mechanism and the role repository. The latter has been refactored in order to keep advantages of the Spring configuration. Spring is taking more and more space within WhiteCat, as demonstrated from the removal of the old Configuration class.
The locking mechanism has been completely rewritten. The locking is a mechanism that allows the role developer to mark (annotate) a proxy method in order to avoid its execution while the proxy itself is undergoing role manipulation. This is useful in order to avoid critical races on proxy mutators. The locking is managed by the ProxyStorage, that is an object that keeps track of all available proxy instances and their manipulation status, providing support for getting the last-updated proxy with a specific proxy identification. The locking mechanism is implemented with an AspectJ aspect that, before the execution of a locked method (i.e., a method with the @Lock annotation), consults the proxy storage in order to see if the proxy is going under manipulation, and in such case can (i) delay the method execution or (ii) avoid the method execution throwing an exception. Each time the role booster starts a role manipulation operation it instruments the proxy storage to lock the proxy, so that the system is aware that the above proxy is going to be manipulated by a proxy. The proxy storage has obtained a "make up" and now stores a wrapper object, called the ProxyStatus, that contains the last manipulated instance of the proxy, some statistics (e.g., how many time it has been manipulated) and a locking object, that is the one the locking mechanism relies on. This means that each proxy has its own locking object, that is used to synchronize Java threads.
Finally, there is a new JUnit test that demonstrates and tests the locking mechanism itself.
venerdì 16 luglio 2010
WhiteCat: a little octopus merge with several features
Today I pushed a little octopus merge (three branches) I have developed during last nights. This commit introduces a new set of features in the WhiteCat framework; such changes are for a long term view of the project and do not touch heavily the user's interface.
First of all now there are a few JUnit tests that, besides testing the framework, can be used as examples for understanding how WhiteCat internally works and how facilities and APIs should be used.
Then comes the support for a customizable proxy cloning. In the past, when a role manipulation was completing, WhiteCat invoked the updateProxy method on a proxy handler in order to copy the proxy status from the old instance to the new one. This works fine if the proxy and the proxy handler are tied together, since the proxy handler will not copy any "extended" status it is not aware of. This is fine for WhiteCat to work, but is not useful for a developer that wants to develop its own proxy class. To solve the problem a new interface has been added, ICloneableAgentProxy, that if applied to a proxy instrument WhiteCat to clone the old proxy instance. Please note that the cloning is manual, that is on the proxy developer, since it is not possible to use the standard Java cloning methodology since this will not allow WhiteCat to work and manipulate proxy classes. To summarize, if you have defined a new proxy and want to keep its internal status, use the ICloneableAgentProxy interface and implement the cloneAgentProxyState(..) method to control the copy field by field.
But how can a developer install his own proxies in the system? Here comes another interesting new feature: WhiteCat now can be fully configured using Spring! This means that the old configuration, based on properties, is no more used (and is deprecated) and it is possible to specify exactly which classes instances should be used as proxy handlers, agents, and even as role booster (so this means you can implement your own!). Of course, introducing Spring lead to a deep refactoring of the main internal structures in order to support dependency injection. The result is that now there are a lot of different interfaces, one for each configurable component.
There is now also a unique factory, implemented by the WhiteCat class. This is not a way to remove factories for configurable objects, but to have a single entry point to get an object instance. The idea is that each object should be created by its factory, and the factory itself should rely on Spring, while the WhiteCat class exposes a common interface to all the factories.
Finally, the most difficult change, is the introduction of a RoleOperation, a wrapper around all role manipulation informations (which agent, which proxy, which role, etc.). This is deeply used by the current role booster implementation, and this means that the booster is now instrumented by such role operation. This is a not fully completed implementation of the Command Pattern; it is lacking the execute command way, that could be added in the future. The adoption of the role operation abstraction opens new ways: it will be possible to fully implement a command pattern, to queue and manage multiple role operations, and to keep a track about who asked for what and what was the result.
lunedì 12 luglio 2010
Fixed a problem with the public role removal
I committed a change to the RoleBooster that fixes a stupid but hard to find problem with the public role removal. Now the Role Booster can correctly remove a role from an agent proxy returning the "un-roled" version of the proxy.
Interestingly the Role Booster was not behaving nicely with a single role case: if an agent assumes a single role, and then wants to immediatly discard it, the booster was continuing to return the same proxy instance (or better, a new one cloned from the current one). For this reason now, when only the role interface is found on the current proxy, the instance returned is a superclass. This is fine with WhiteCat because the Role Booster guarantees that each "roled" proxy is a subclass of the starting proxy class, so the inheritance chain is growing to the bottom.
venerdì 18 giugno 2010
WhiteCat @ CTS 2010
WhiteCat has been presented as a poster at CTS 2010, where people appeared really interested in this dynamic role framework. It is a small step for WhiteCat to grow and become more visibile, but it is an important one: as much as the framework gains in popularity, the much its adoption and improvement will happen!
Here there is an image of the poster that can be used to understand at a glance the WhiteCat architecture and idea.

For a more detailed introduction to WhiteCat please see these blog posts or read the article L. Ferrari, and H. Zhu, “Making Agent Roles Perceivable Through Proxy Bytecode Manipulation,” in Proc. of the ACM/IEEE International Symposium on Collaborative Technologies and Systems (CTS’09), Baltimore, MA, 2009, pp. 408-416 (Best Paper Nomination)
giovedì 18 febbraio 2010
Throw your code away....or release it as OpenSource!
Internet is full of discussions about the importance of OpenSource: OpenSource code is available for everyone, allows you to learn, depending on the license allows you to modify and adapt the software to your needs and, if the code is Free Software, it costs you almost nothing. In this post I want to point out another important reason: research activity. I don't mean what kind of research you can do with OpenSource code, but what quality of code you can produce during your research. It seems to me that almost every research activity produces code of very poor quality, and puts such code under a prototype umbrella. Most of the time, producing a prototype make researcher feeling as they must produce nothing more than a proof of concept. This is true, but leads to a very waste of resources and efforts: if the proof of concept works, before it goes to production it needs refinements and code rewriting, on the contrary if the proof of concept does not work, well, it must be rewritten. Since the proof of concept (the prototype) is kept private and usually does not get out of the laboratory bounds, it is allowed to be a mess of code. Once the code will be distributed outside the laboratory, it will become more and more beauty and clean. Staying confined within research lab boundaries means that the prototype does not have users. This also means that the XP paradigm cannot be applied, or it does not make sense to apply it: there is no need to release often, there is no need to keep the code clean and the repository always stable (or at least filled with code that does not have compile errors).
Why and how OpenSource can help researchers producing good quality code? First of all, releasing a project or a prototype publicly means you could have users, and users can help you (or bother you) to find problems, suggest patches, and sometimes can make some work on your behalf. Most notably, releasing the code means you have to keep it documented, keep it clean and at least easy to compile and run. Releasing a product as OpenSource means you are subscribing a contract between you and (possible) users, and you are asked to keep the project on the rails. This does not mean you have to lead the project forever, but means that the project can live forever, surviviving problems.
So why does not researcher release OpenSource code? Well, most of them do, but a lot of project dies behind a laboratory walls. The main reason is that researches are afraid someone else can steal their brilliant ideas having access to their implementation. This lies two problems:
- the idea should be a model, not an implementation. The implementation is language and architecture dependent, and evvery good developer can do it;
- researches do not know OpenSource licenses, that can protected and guard their work and ideas.
Just as an example: I started studying and working on JikesRVM before version 2, when it was not a full OpenSource project. At that time the code was really undocumented, organized in a single directory (for code cleanup issues) and it was difficult to get internal details without digging the code. Now, that the project is hosted as OpenSource, its code structure is well organized, the documentation can really help new users and the list of contributors and users has grown as well as the list of features. As a counter-example, I worked in a research project about Ambient Intelligence called LAICA. In such project I have seen a lot of commercial partners producing very low quality code, and the reason I perceived was the whole project had has to be a proof of concept, and in the case it was proved to be good, other funds would have been available to support its production-rewriting.
So, when you are starting a new research project, ask yourself if you can release at least a part of it as OpenSource, and in the case, do it. I believe it's really worthing.
domenica 31 gennaio 2010
Java Actors and the missing FIPA
Java Actors are becoming a well known way to build distributed, parallel, message-passing based applications. The theory behind actors is very similar to that behing agents, even if an agent more complex than an actor because have a smart part (sometimes called agenthood). However, since new Java actor frameworks are growing, I don't understand why FIPA is not coming into the field defining some kind of standards for such paradigm. It could be the best of both world, but as far as I know there is only a paper that tries to merge both.
mercoledì 25 novembre 2009
Compile time constraints and runtime constraints: WhiteCat merges both!
Due to the reviews on a WhiteCat paper I received, and the claims from a colleague of mine, I decided to write a little post about my way of thinking OOP and how I conceive it with WhiteCat.
I started developing serious applications using Java version 1. If you remember, at that time there were no fancy features, so the only thing you could have to do to decouple your code was to have a good OOP design. What is a good OOP design? It is a strictly typed system.
Am I a strictly-typed kind of developer? Yes.
In my early stage of software designer I was used to create classes and interfaces as it was raining cats and dogs! Then I read THE book about Perl (Programming Perl) and a statement by Larry Wall really impressed me: Larry wrote that there must a balance between programming-in-a-rush and programming-by-presumption. What does it mean? It means (to me) that if you are a pure OOP designer/developer you will start thinking that you are not developing only a piece of software to solve an assigned problem, but you are creating a creature that everybody could/would use. This leads to a class/interface storm, since you are taking into account every possible use of your piece of software. I was such a developer!
Now I've changed my mind, and I've found a good balance between rush and presumption.
How does my OOP mindset connect to the WhiteCat approach? Well, of course WhiteCat is a creature of mine, and therefore it has been developed following my ideas and design/developing habits. But this of course not the answer you want to read.
WhiteCat is a very dynamic system, and usually dynamism is at the opposite of strong typing (think to Python for instance). Since I am a strictly-typed designer/developer, how can I accept a very dynamic system like WhiteCat?
Short answer: Liskov substitution principle is guarantee to work, so the type system is ensured to work.
Do you need a more detailed answer?
When you compile an application you accept the compiler rules. A strict compiler leads to a typed system (secure), while a weak compiler leads to an untyped system (more dynamic, less secure).
WhiteCat agents, roles, and framework itself is compiled thru a standard Java compiler (well, to be onest thru an AspectJ one), so WhiteCat components obey the same compiler rule.
But WhiteCat allows developers to dynamically change the class definition at runtime; does it means that compile rules are overtaken? No, since WhiteCat guarantees the Liskov substitution principle to work. But this is not all folks: WhiteCat imposes compile-time constraints at runtime! This is the very soul of WhiteCat: being able to start from a strongly-typed system (your agents/role compiled thru a Java compiler) and to modify them at runtime as they were compiled in a different way (i.e., starting from modified sources).
So WhiteCat starts from a typed system and leads to a typed system, but in the middle it is able to change the types in order to improve your agents/roles.
Was this the same as RoleX (a.k.a. BlackCat) did? No, because BlackCat was changing dynamically the agent class making the Liskov substitution principle not applicable. In other words, BlackCat was very dynamic, but started from a typed system to get to an untyped (and unmanageable) system. This is the real difference between WhiteCat and BlackCat.
I started developing serious applications using Java version 1. If you remember, at that time there were no fancy features, so the only thing you could have to do to decouple your code was to have a good OOP design. What is a good OOP design? It is a strictly typed system.
Am I a strictly-typed kind of developer? Yes.
In my early stage of software designer I was used to create classes and interfaces as it was raining cats and dogs! Then I read THE book about Perl (Programming Perl) and a statement by Larry Wall really impressed me: Larry wrote that there must a balance between programming-in-a-rush and programming-by-presumption. What does it mean? It means (to me) that if you are a pure OOP designer/developer you will start thinking that you are not developing only a piece of software to solve an assigned problem, but you are creating a creature that everybody could/would use. This leads to a class/interface storm, since you are taking into account every possible use of your piece of software. I was such a developer!
Now I've changed my mind, and I've found a good balance between rush and presumption.
How does my OOP mindset connect to the WhiteCat approach? Well, of course WhiteCat is a creature of mine, and therefore it has been developed following my ideas and design/developing habits. But this of course not the answer you want to read.
WhiteCat is a very dynamic system, and usually dynamism is at the opposite of strong typing (think to Python for instance). Since I am a strictly-typed designer/developer, how can I accept a very dynamic system like WhiteCat?
Short answer: Liskov substitution principle is guarantee to work, so the type system is ensured to work.
Do you need a more detailed answer?
When you compile an application you accept the compiler rules. A strict compiler leads to a typed system (secure), while a weak compiler leads to an untyped system (more dynamic, less secure).
WhiteCat agents, roles, and framework itself is compiled thru a standard Java compiler (well, to be onest thru an AspectJ one), so WhiteCat components obey the same compiler rule.
But WhiteCat allows developers to dynamically change the class definition at runtime; does it means that compile rules are overtaken? No, since WhiteCat guarantees the Liskov substitution principle to work. But this is not all folks: WhiteCat imposes compile-time constraints at runtime! This is the very soul of WhiteCat: being able to start from a strongly-typed system (your agents/role compiled thru a Java compiler) and to modify them at runtime as they were compiled in a different way (i.e., starting from modified sources).
So WhiteCat starts from a typed system and leads to a typed system, but in the middle it is able to change the types in order to improve your agents/roles.
Was this the same as RoleX (a.k.a. BlackCat) did? No, because BlackCat was changing dynamically the agent class making the Liskov substitution principle not applicable. In other words, BlackCat was very dynamic, but started from a typed system to get to an untyped (and unmanageable) system. This is the real difference between WhiteCat and BlackCat.
Iscriviti a:
Post (Atom)